
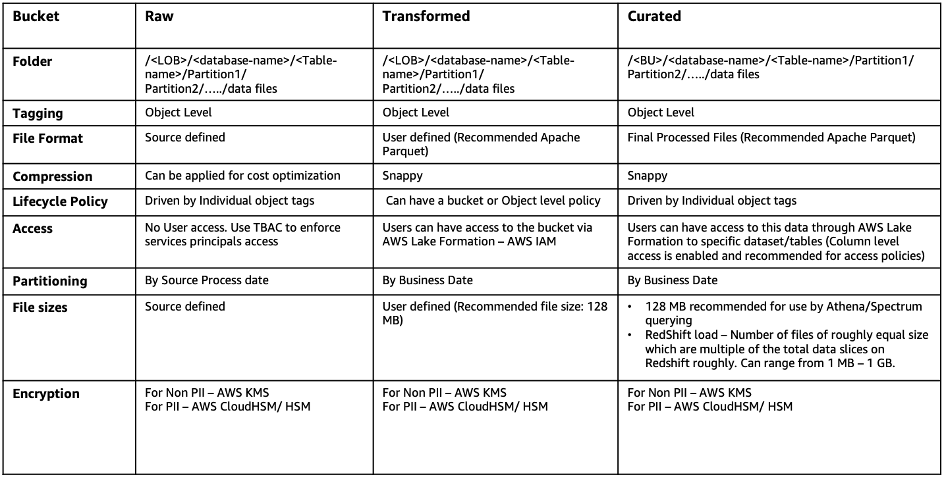
A data lake can be broadly categorized across four distinct buckets:
- Raw data – Data received from the source without any change. This data shall be immutable. The data formates include structured, semi structured, and unstructured data objects such as databases, backups, archives, JSON, CSV, XML, text files, or images.
- Transformed – When a data is processed such as normalized to a specific use case for performance improvement and cost reduction. Also, data may be transformed into columnar data formats, such as Apache Parquet and Apache ORC, which can be used by Amazon Athena. In this case, data is only transformed but not cleansed.
- Curated –The data is further enriched by blending it with other data sets to provide additional insights. At this stage the data are cleansed and optimized for analytics, reporting, and so on.
Referencess:
- AWS S3 – https://docs.aws.amazon.com/whitepapers/latest/building-data-lakes/data-lake-foundation.html