Python has many competing libraries. There are few that are used widely and few that are up and coming. In this report, we cover the performance of Python library that queries the database and creates a data structure. This is critical for application, AI/ML models and any script that is accessing database.
The goal of the experiment is to determine which library perform under the same conditions. The setup is described in detail in the experiment section. Following are the libraries that are part of the experiment.
We considered Dask as a port of experiment. After investigating further, Dask is distributed dataframe and our experiments have only the data structure that are in one single machine. Thus, the Dask was dropped
Note: Dask and Polars, not able to use the SqlAlchemy v2.x as the v2 is quite different semantic than the v1.x libraries. However, Pandas only read_sql method worked with the SqlAlchemy v2.
Python Libraries involved:
Database libraries
- SqlAlchemy v 2.0.9 (https://www.sqlalchemy.org/), it depends on psycopg2
- Psycopg2 (https://www.psycopg.org/)
- Connectorx v0.2.3 (https://pypi.org/project/connectorx/0.2.3/)
Data Structure libraries
- Pandas (https://pandas.pydata.org/)
- Polars (https://github.com/pola-rs/polars)
- Dask (https://www.dask.org/) (not part of experiment)
Environment
- Database: Postgres ( locally installed), V
- Data: Single table with 18 Columns and 2.84 Million Rows; size: 411 MB, with no indexes
- Machine:
- MSI model: PX60 6QE,
- CPU: Intel I7 @2.6 GHz 8 cores,
- Memory: 32GB, HD: Solid state
- OS: Ubuntu 22.04
Experiments
Experiment cases:
Data and Database setup: All the process is doing the same query “Select * from table.” The query does not have a where clause and it is selecting the whole table. The table does not have index.
There are three flavors, they are
- Case 1 : Use the SqlAlchemy Engine (connection pooling) and use straight sql to query the database. The result is extracted in the list with list generation operation.
- Case 2: Use the psycopg2 library directly to run the query and create list from the result set using the list generation operation.
- Case 3: Use Pandas read_sql to query the data and create the Panda Dataframe. The Panda uses SqlAlchemy Engine (v2) for the database query.
- Case 4: Use Panda read_sql to query the database and create the Panda Dataframe. The Panda uses psycopg2 library directly.
- Case 5: Use Polars read_sql to query the database and create the Polars Dataframe. The Polars uses connectorx library instead of psycopg2.
Experimental Results:
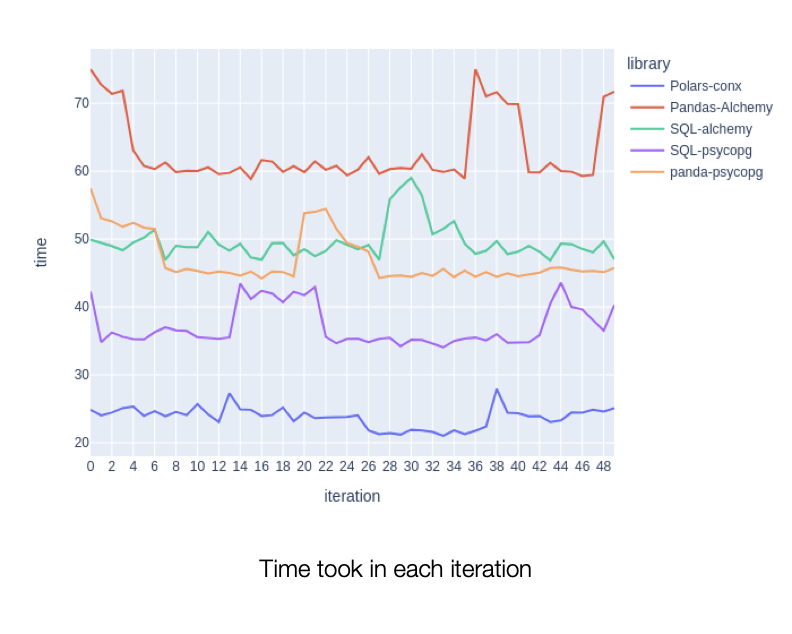
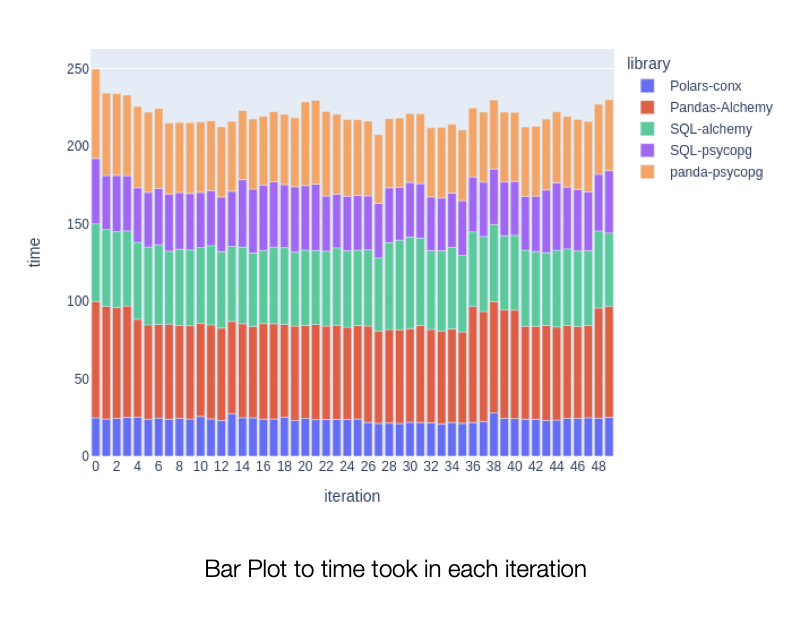
The call was made 50 times in a loop. Each case is run 10 times before the 50 iteration is started. Each case is run in sequence that is one after another. There was no process running in the machine besides the Postgres and the code.
Since, the query is run before the actual 50 iteration, the Postgres db would have cached data and query and there would not be follower advantage.
Note:
- *-psycopg – the code is creating connection using psycopg package
- *-Alchemy – the code is using the SQLAlchemy’s ‘engine’
- *-Conx – the code is using the conntionx package
Following table shows the summary statistics.
| Cases | Average | Max | Min | StdDev | Relative Performance |
| Panda-psycopg | 47.0266 | 57.4874 | 44.2253 | 3.5100 | 2x |
| Pandas-Alchemy | 62.9166 | 75.0353 | 58.8501 | 4.9626 | 2.7x |
| Polars-Conx | 23.7622 | 27.9369 | 21.0048 | 1.5069 | 1x |
| SQL-Alchemy | 49.5676 | 59.0215 | 46.8378 | 2.6135 | 2.1x |
| SQL-psycopg | 37.1867 | 43.5696 | 34.0521 | 2.9547 | 1.6x |
The expectation was that Alchemy connection pool should have performed better than creating a new connection each time. However, the result shows that using Alchemy Engine (connection pool) is costlier than creating a new connection each time from psycopg package.
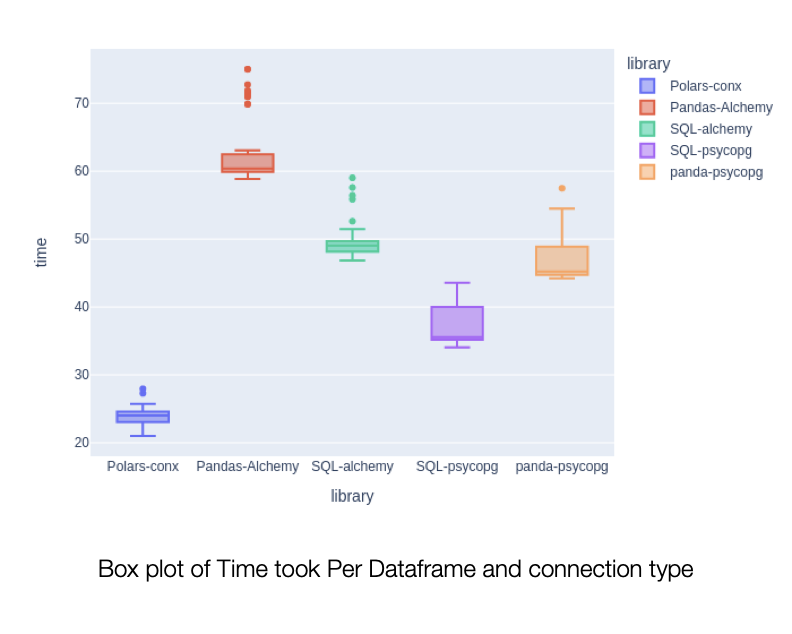
In this experiment, the Polars was clear winner with 2x over Panda and psycopg and almost 3x over Pandas and SQLAlchemy dependencies.
Box plot shows Polars on the bottom left corner as clear winner and better performing data frame when loading data from the postgres.
The following plots shows elapsed time over the 50 iteration.